Spark运行模式
运行模式
单机
本地模式
伪分布模式
集群
Standalone模式
外部资源调度框架
YARN
Mesos
运行流程
无论何种模式, Spark的整体运行流程如下:
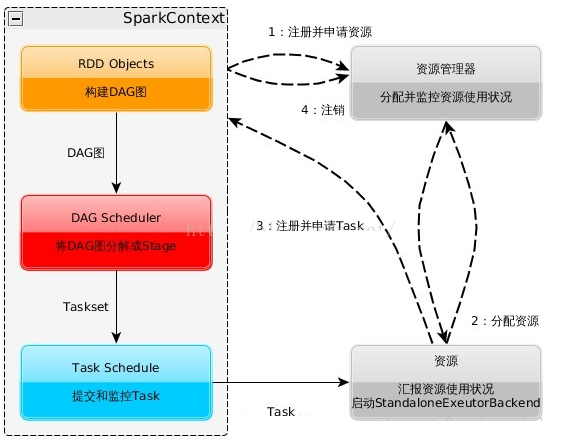
构建Application的运行环境, 启动SparkContext, 即Driver
SparkContext向资源管理器(Standalone/YARN/Mesos等)申请运行所需的Executor资源
Executor向SparkContext申请Task
SparkContext将Application构建成DAG图, 并将其根据一定的规则拆分成Stage, 在通过内部的TaskScheduler将拆分成的Task分发给Executor来执行
Task在Executor上运行, 运行完释放所有资源
Spark运行过程中比较有特点的地方有:
Spark与资源管理器无关, 只要能够获取executor进程, 并能保持相互通信就可以了
提交SparkContext的Client应该靠近Worker节点, 因为Application运行过程中SparkContext和Executor之间有大量的信息交换
Standalone运行模式
Standalone模式采用经典的Master/Slaves架构, 主要的节点有三种:
Client节点
Master节点
Worker节点
而Driver(SparkContext)既可以运行在Master节点上, 也可以运行在本地Client节点上:
用spark-shell交互式工具提交Spark的Job时, Driver在Master节点上运行
用spark-submit工具提交Job时, Driver是运行在本地Client端上的
无论Driver运行在哪种节点上, 整个运行流程如下:
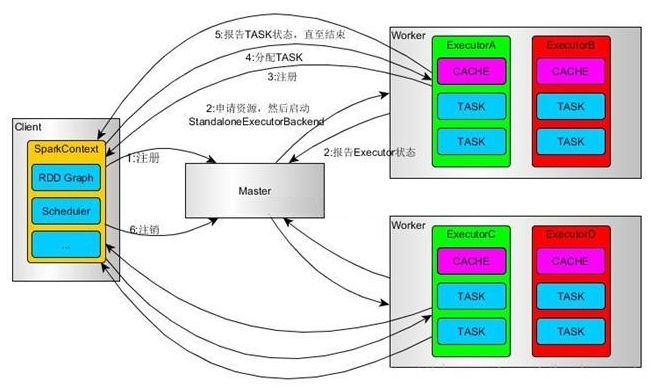
SparkContext连接到Master, 向Master注册并申请资源(CPU, 内存等)
Master根据SparkContext的资源申请要求和Worker心跳周期内报告的信息决定在哪个Worker上分配资源, 然后在该Worker上获取资源, 启动StandaloneExecutorBackend, 向SparkContext注册
SparkContext将Applicaiton代码发送给StandaloneExecutorBackend, 并且SparkContext解析Applicaiton代码, 构建DAG图, 并提交给DAGScheduler分解成Stage, 然后将Stage提交给TaskScheduler, TaskScheduler负责将Task分配到相应的Worker, 最后提交给StandaloneExecutorBackend执行
StandaloneExecutorBackend会建立Executor线程池, 开始执行Task, 并向SparkContext报告, 直至Task完成
所有Task完成后, SparkContext向Master注销, 释放资源
YARN模式
Spark on YARN模式根据Driver在集群中的位置分为两种模式:
YARN-Client模式, Driver在客户端本地运行
YARN-Cluster/YARN-Standalone模式, Driver运行在YARN中的某个NodeManager上
YARN-Client
YARN-Client工作流程如下:
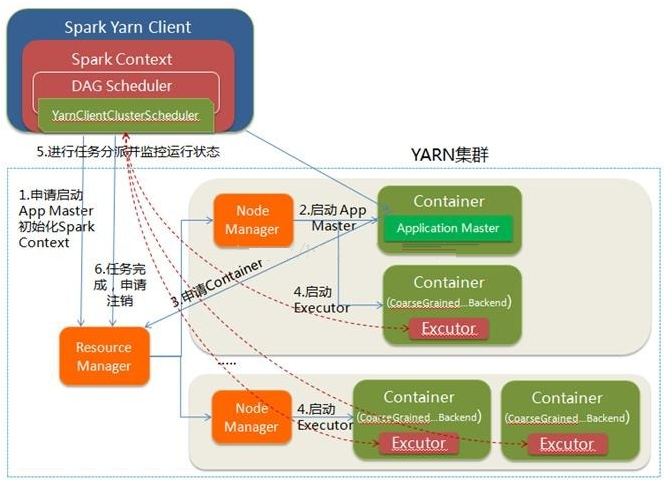
Client向ResourceManager申请启动ApplicationMaster, 同时, 在Client上初始化创建SparkContent(DAGScheduler, TASKScheduler等)
ResourceManager收到请求后, 在集群中选择一个NodeManager, 为该应用程序分配第一个Container, 要求它在这个Container中启动应用程序的ApplicationMaster
与YARN-Cluster的区别在于: 该ApplicationMaster只与SparkContext进行联系和资源的分派
Client中的SparkContext初始化完毕后, 与ApplicationMaster建立通讯, ApplicationMaster向ResourceManager注册, 根据任务信息向ResourceManager申请资源(Container)
ApplicationMaster申请到资源Container后, 与对应的NodeManager通信, 要求对应的Container中启动Executor(CoarseGrainedExecutorBackend), 启动后会向Client中的SparkContext注册并申请Task
SparkContext分配Task给Executor执行, Executor运行Task并向Driver汇报运行的状态和进度, 让Client随时掌握各个任务的运行状态, 从而可以在任务失败时重新启动任务
应用程序运行完成后, Client的SparkContext向ResourceManager申请注销并关闭自己
YARN-Cluster
在YARN-Cluster模式中, 当用户向YARN中提交一个应用程序后, YARN将分两个阶段运行该应用程序:
Driver作为一个ApplicationMaster在YARN集群中先启动
由ApplicationMaster创建应用程序, 然后为它向ResourceManager申请资源, 并启动Executor来运行Task, ApplicationMaster同时监控它的整个运行过程
整体的运行流程如下:
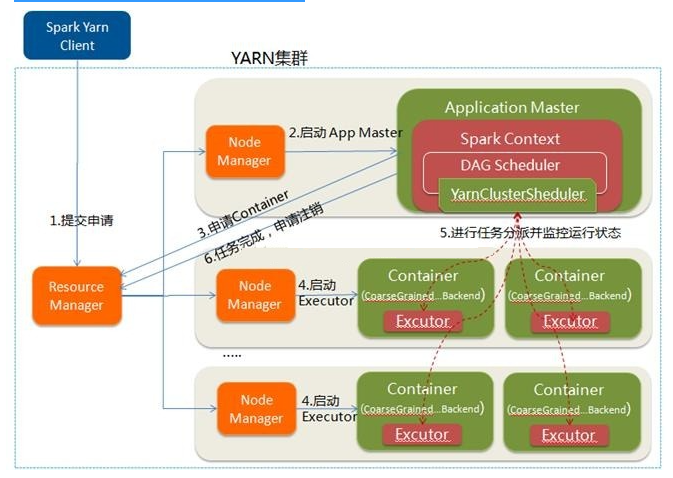
Client向YARN提交应用程序(启动ApplicationMaster的命令, ApplicationMaster程序, 需要在Executor中运行的程序等)
ResourceManager收到请求后, 在集群中选择一个NodeManager, 为该应用程序分配第一个Container, 在这个Container中启动应用程序的ApplicationMaster, 然后ApplicationMaster进行SparkContext的初始化
ApplicationMaster向ResourceManager注册
这样用户就可以通过ResourceManager查看应用程序的运行状态
ApplicationMaster采用轮询的方式通过RPC协议为各个任务申请资源, 并监控它们的运行状态直到运行结束
ApplicationMaster申请到资源Container后, 与对应的NodeManager通信, 在获得的Container中启动Executor(CoarseGrainedExecutorBackend)
Executor启动后会向ApplicationMaster中的SparkContext注册并申请Task
ApplicationMaster中的SparkContext分配Task给Executor执行, Executor运行Task并向ApplicationMaster汇报运行的状态和进度, 让ApplicationMaster随时掌握各个任务的运行状态, 从而可以在任务失败时重新启动任务
应用程序运行完成后, ApplicationMaster向ResourceManager申请注销并关闭自己
YARN-Client和YARN-Cluster的区别
在YARN中, 每个Application实例都有一个ApplicationMaster进程, 它是Application启动的第一个容器, 它负责和ResourceManager打交道并请求资源, 获取资源之后告诉NodeManager为其启动Container, 因此YARN-Cluster和YARN-Client模式的区别其实就是ApplicationMaster进程的区别
YARN-Client模式下, ApplicationMaster仅仅向ResourceManager请求Executor, Client会和请求的Container通信来调度他们工作, 也就是说Client不能离开
YARN-Cluster模式下, Driver运行在ApplicationMaster中, 它负责向YARN申请资源, 并监督作业的运行状况
当用户提交了作业之后, 就可以关掉Client, 作业会继续在YARN上运行, 因而YARN-Cluster模式不适合运行交互类型的作业
参考资料
最后更新于